How Ads Find You in 100 Milliseconds
AdTechData EngineeringYou opened a webpage. Maybe it was news, maybe it was a recipe, maybe it was whatever you Googled at 11pm that you'd rather not discuss. Either way, before you've read a single word, something happened without your knowledge, though technically, buried in a terms-of-service document that nobody reads, you did agree to it.
An ad appeared.
Easy to ignore, easy to scroll past. But in the 100 milliseconds between your browser requesting that page and the ad showing up in the corner (roughly the time it takes to blink), a live financial auction ran, a winner was picked, and a company paid real money to reach you. Not "people browsing the internet." You, specifically. Or at least the version of you that exists as a string of anonymized identifiers in several databases you've never heard of.
I've worked inside AdTech for over a decade, mostly building the data infrastructure that feeds into this system. The question I get most often, from people who find out what I do, is some version of: "Wait, how does it know?" They always mean the shoes. Everyone has a shoe story. You looked at running shoes on Tuesday. By Wednesday you're being followed by running shoe ads on every website you visit, including, somehow, a website about medieval history. That's not a coincidence and it's not magic. It's a system, and it works in ways that are both more mundane and stranger than most people expect.
Here's how it actually works.
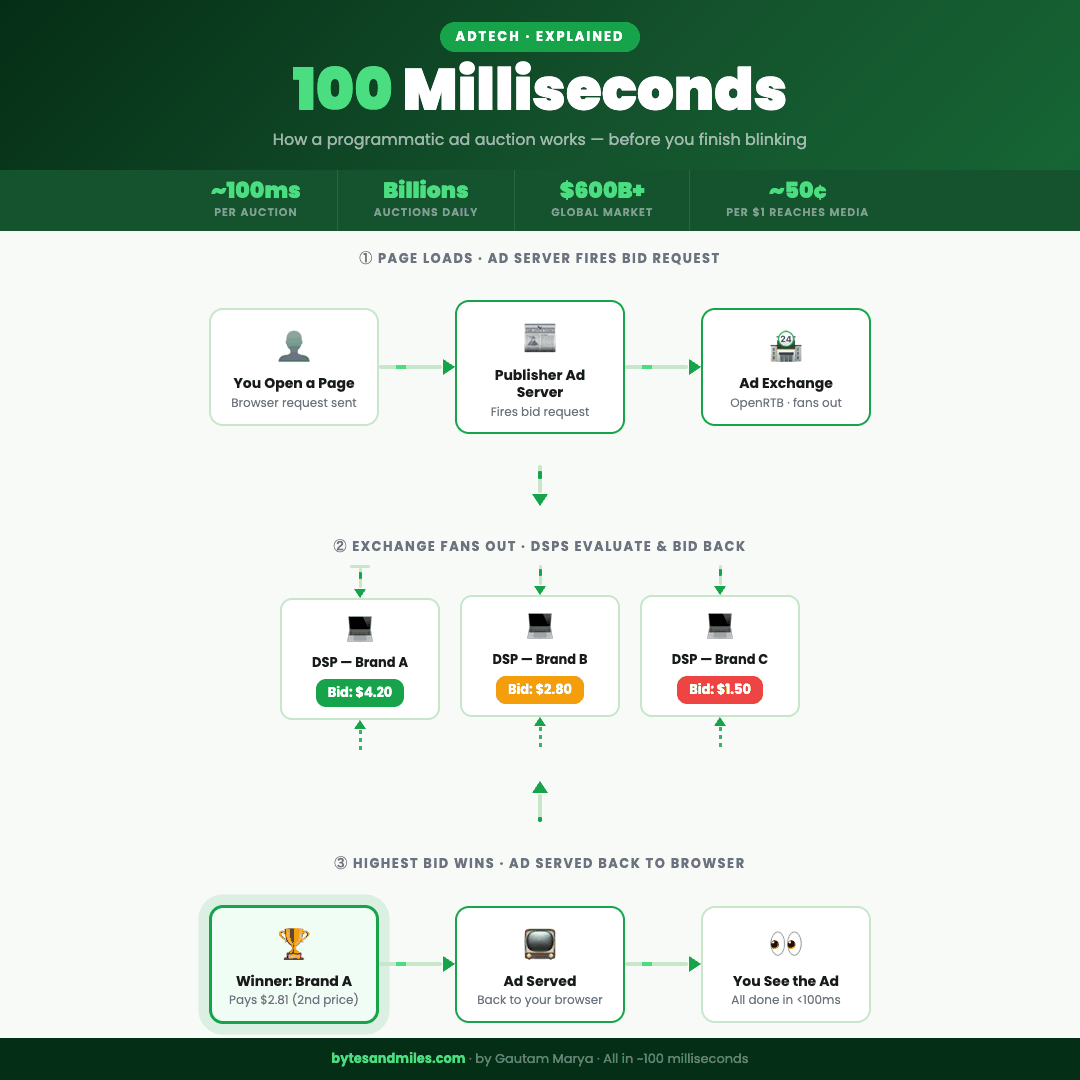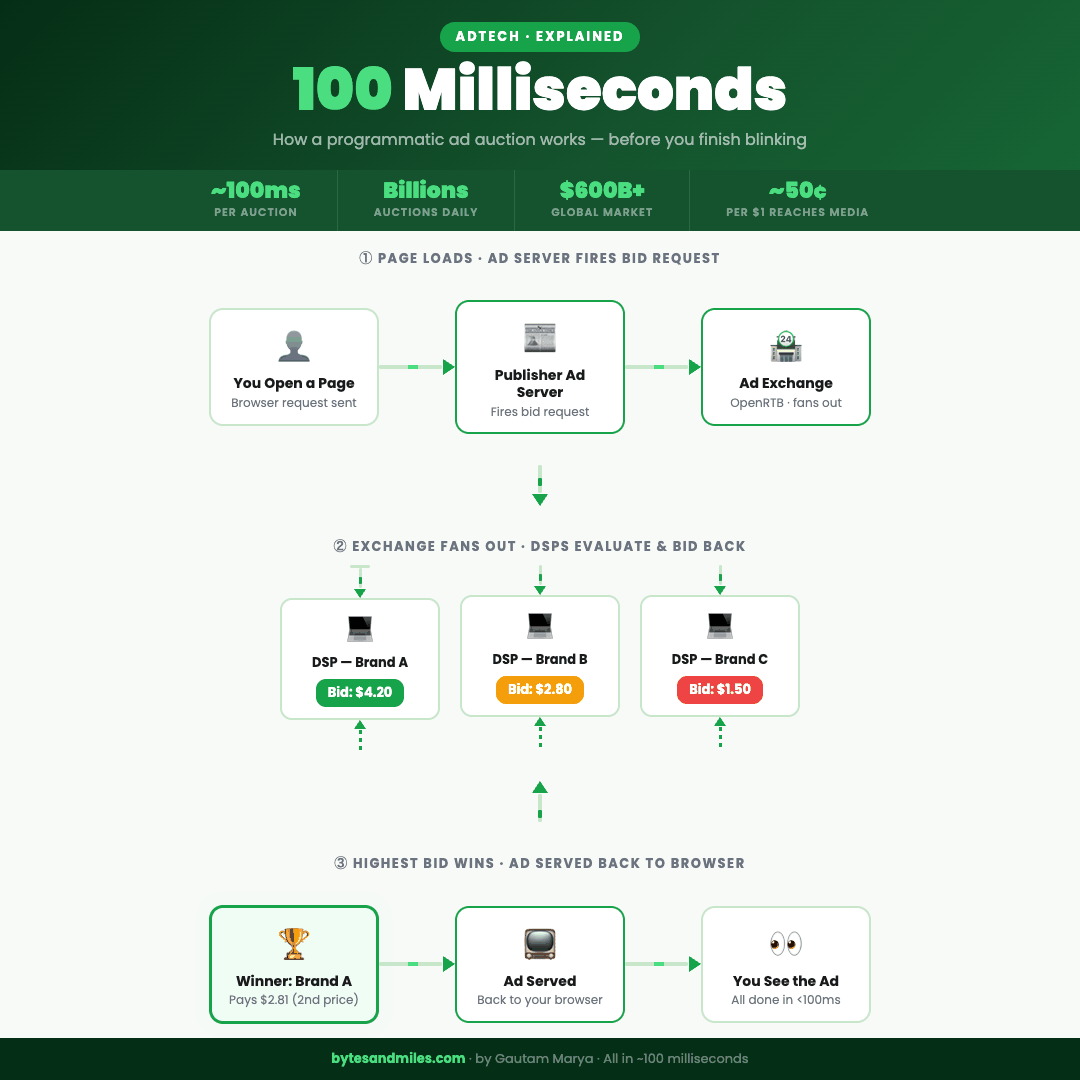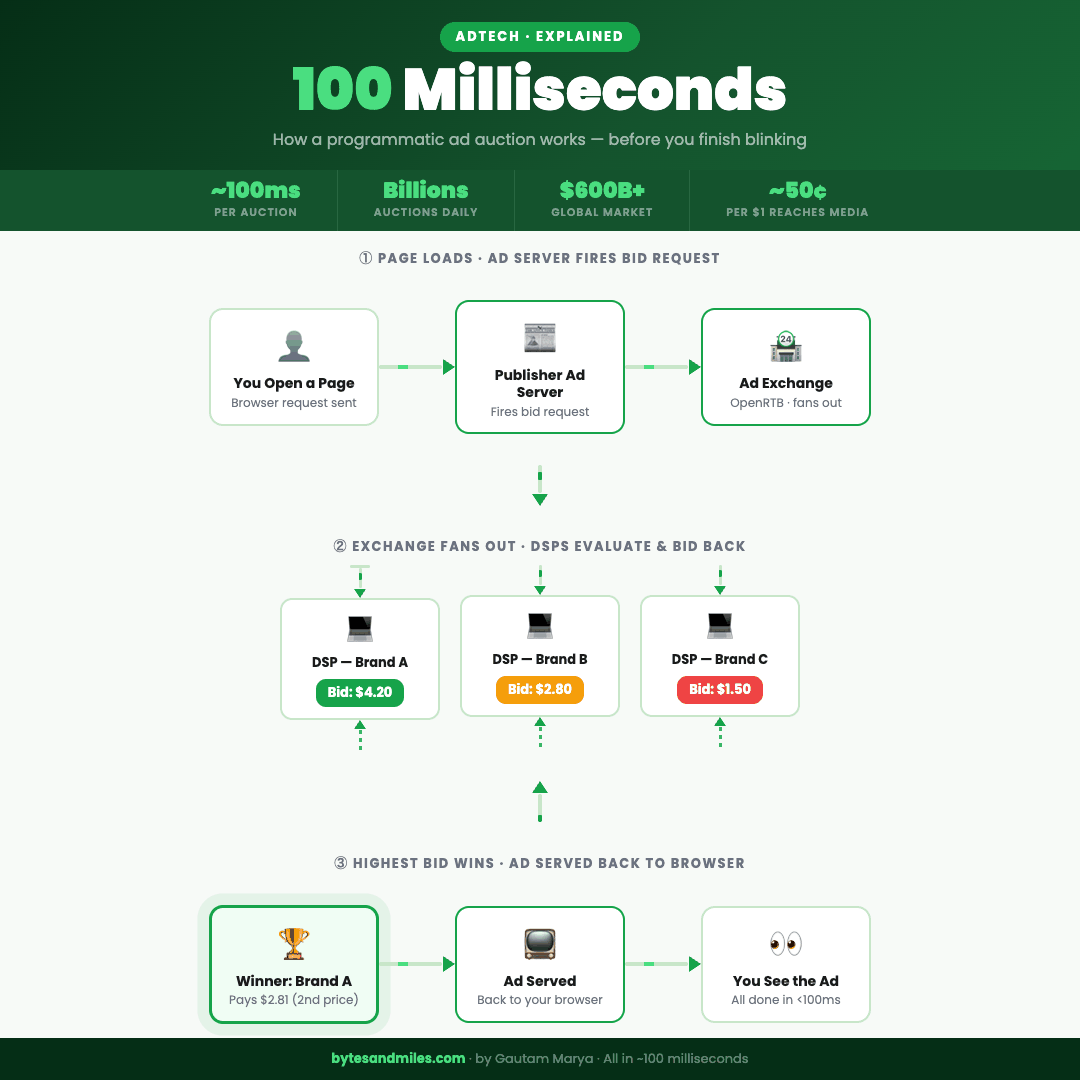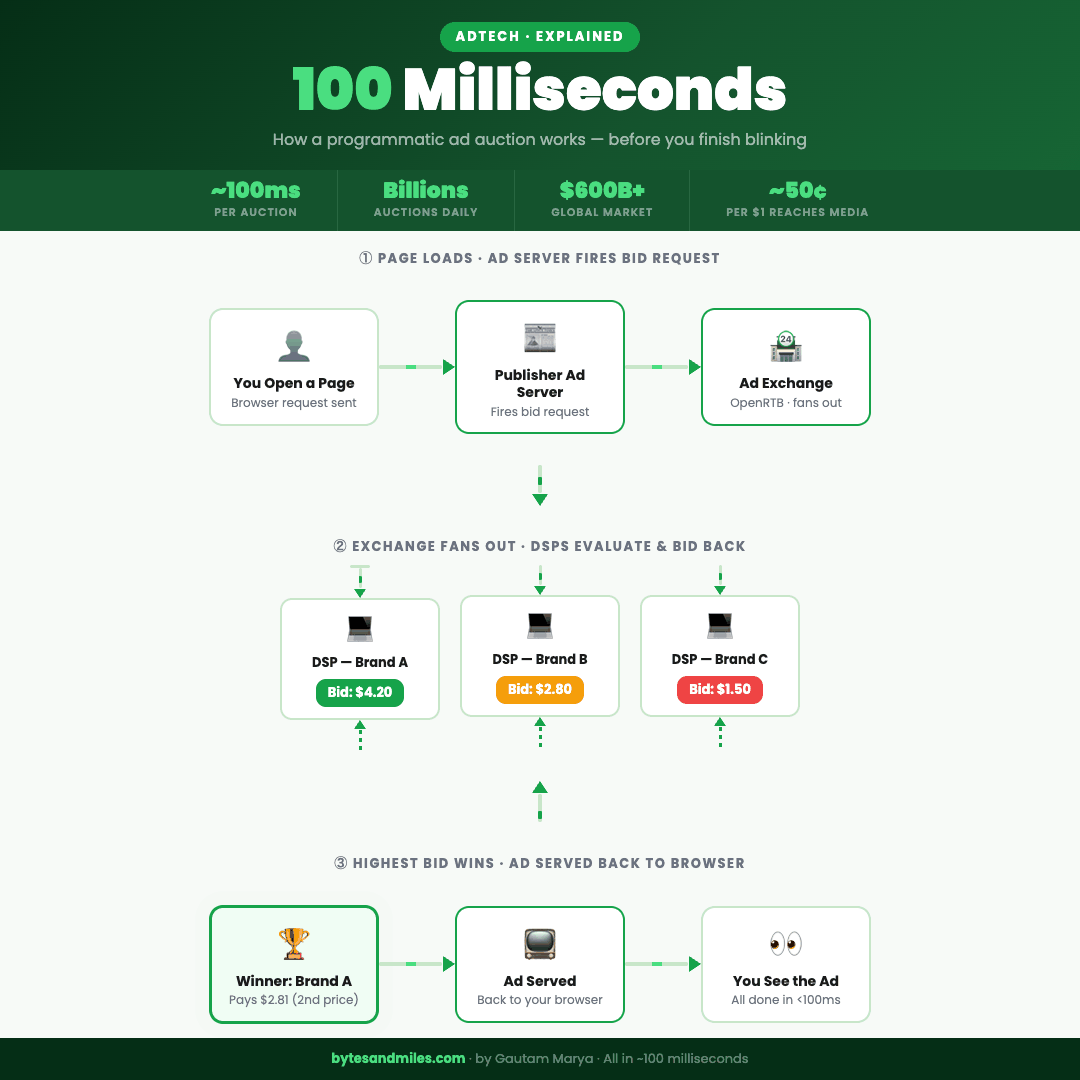
The full auction flow, from page load to ad served, in under 100 milliseconds.
The Publisher's Problem
Every page on the internet that shows you an ad is, at that exact moment, running a live auction. Multiple companies bidding against each other, in real time, for the right to put their creative in front of your eyes. The highest bidder wins, the ad gets served, and the whole thing resolves before the page finishes loading. You never see any of it.
But before that auction can happen, someone has to set it up and call it. That's the publisher's job.
Every major website runs an ad server, which is exactly what it sounds like: a server whose entire purpose is deciding which ads go where and for how much. When you hit a page on a news site, the ad server fires before the article has even finished loading. It looks at the available ad slots on the page and thinks, in the most mercenary way possible: what can I get for these?
For most of AdTech's history, the answer came from a system called a waterfall. Publishers would offer each impression to their highest-paying partner first, wait for a response, then work down the list to cheaper and cheaper buyers until someone took it. The logic made sense on paper. In practice it was slow, and it left money on the table, because a buyer lower on the list might have paid more if they'd been asked first. Nobody knew, because nobody asked.
Header bidding fixed this. Instead of going down a list one at a time, the publisher now broadcasts the impression to multiple exchanges simultaneously, before the page even finishes loading. Every exchange gets a shot at the same time and the best offer wins. It's the difference between quietly asking one person if they want your spare concert ticket, waiting for them to say no, then asking the next person, and just texting the whole group chat at once.
That broadcast goes out as a bid request, and it carries more information than you'd expect. The size and position of the ad slot. The URL and content category of the page. Your device type, operating system, and browser version. A rough geographic location. The time of the request. And crucially, an identifier, a string of characters that represents you (anonymously, technically) and is the key that unlocks all the targeting logic that comes next.
The exchange takes all of this, formats it into a standardized structure called OpenRTB (the shared language every system in this chain speaks), and fans it out to every Demand-Side Platform, or DSP, competing for the impression. A DSP is where advertisers live: the platform where they load their campaigns, set their budgets, and place their bids. Think of the exchange as the marketplace and the DSP as each buyer's stall inside it. The DSPs have roughly 50 to 100 milliseconds to respond. We'll get into what happens inside them next.
In human terms, 100 milliseconds is nothing. In compute terms, it's a lot of logic running very fast.
The Auction
When a bid request lands at a DSP, the platform doesn't just immediately throw out a number. It runs the request through a stack of checks first, and most impressions don't even make it through.
The first filter is eligibility. Does this impression match any live campaign? Is the page on the advertiser's blocklist? Brand safety is a real thing in this industry: a luxury car brand does not want their ad appearing next to a breaking news story about a fatal crash, and a children's toy company really doesn't want to show up on certain corners of the internet. DSPs maintain these blocklists and check them in milliseconds. Is the inventory quality high enough? Is the user's identifier associated with any audience the advertiser actually wants to reach? If none of that clears, the DSP returns nothing. No bid, no spend, no problem.
If the impression does clear, the DSP runs a valuation. How much is this specific impression, for this specific user, on this specific page, at this specific moment, actually worth? That number comes from a combination of how similar inventory has performed historically, a predicted probability that this particular user will do whatever the advertiser wants them to do (click, buy, sign up), and what the advertiser has set as their maximum. The result is a bid, returned in a few dozen milliseconds.
Now here's where it gets interesting. The exchange collects every bid that came back in time and runs the auction. For most of AdTech's history, this used a second-price model, borrowed from the world of auction theory. The winner pays the second-highest bid, plus a small increment, not their own bid. Think eBay: you set your maximum at $100, someone else bids $60, and you win at $61. You don't pay $100 just because you were willing to. The idea is that it encourages honest bidding, because there's no advantage to strategically lowballing and no penalty for bidding what something is genuinely worth to you.
This worked well for buyers. In 2019, most major exchanges quietly switched to first-price auctions, where the winner pays exactly what they bid. Coincidentally, this also meant exchanges made more money. Buyers suddenly had to think carefully about not overbidding, because every dollar above the clearing price was just money left on the table. This gave rise to a whole category of software called bid shading, which tries to estimate the minimum you need to bid to win and submits something just above that. It's an entire class of algorithms dedicated to second-guessing a system that itself replaced an older system specifically to stop that kind of guessing. AdTech contains multitudes.
The full sequence, from bid request going out to the winning ad being served back to your browser, closes in under 100 milliseconds. While you were squinting at the headline, an auction ran, a winner was picked, and somewhere a campaign budget just went down by a fraction of a cent.
Who You Are, On Paper
Every bid request carries an identifier. That identifier is the thing that makes targeted advertising work, and understanding what it actually is goes a long way toward demystifying the shoe situation.
For most of the internet's ad-supported history, that identifier was a third-party cookie. A cookie is a small file that a website drops in your browser to remember things about you. First-party cookies are benign: they're how a site remembers you're logged in, or that you left something in your cart. Third-party cookies are different. They're dropped by a company that isn't the site you're actually on, an ad exchange, a data provider, a tracking platform, and they follow you across the internet. Visit a page about running gear, a cookie gets set. Visit a page about travel, another one does. Visit enough pages across enough sites, and a data broker somewhere has quietly assembled a behavioral profile of you without ever knowing your name. Just a cookie ID and a list of everything it's been associated with.
It sounds sinister. The reality is more boring: you're not a person in their system, you're a row in a database with a long list of content categories next to it.
On mobile, the equivalent is the advertising ID. Every Android phone has a GAID and every iPhone has an IDFA, unique identifiers that apps can read and send back to data platforms. This worked exactly like cookies until Apple introduced App Tracking Transparency in 2021, which asked users a simple question: "Would you like to be tracked across apps?" The answer, from the overwhelming majority of iPhone users, was a hard no. That single permission prompt wiped out a significant chunk of mobile ad targeting overnight. The AdTech industry called it catastrophic. iPhone users mostly didn't notice.
Identity graphs are the next layer. A company that runs an identity graph maintains a database dedicated to connecting all of these signals: this cookie, this device ID, this hashed email address, and this IP address are probably all the same person. They build this by observing users log into the same account across different environments, or by buying and merging data from multiple sources, or both. The more connection points they've observed, the more confident the match. Picture a detective's board with strings connecting different clues to the same suspect, except instead of solving a crime, the goal is to figure out whether the person who reads the news on their laptop in the morning is the same person scrolling their phone at night, so someone can sell them a mattress.
The result is that by the time your bid request reaches a DSP, the identifier in it has likely already been matched against a profile with behavioral attributes attached: content categories consumed, purchases inferred, life stage estimated. That profile gets compared against audience segments the advertiser paid to target, and a bid decision follows in milliseconds.
It's also worth knowing that this whole identity layer is genuinely unstable right now. Safari and Firefox blocked third-party cookies years ago. Chrome spent years threatening to follow, ran a very public process to build alternatives, and then in 2024 decided not to remove cookies after all. The alternatives, universal IDs built on consented email hashes, contextual targeting that ignores identity entirely, first-party data strategies where publishers build their own logged-in audiences, are all in various states of "works, but not quite as well." The identity part of AdTech is the part nobody has fully figured out, including the people building it.
Why That Specific Ad
Now we can actually answer the shoe question.
An audience segment is a list of identifiers that share some behavioral attribute. "In-market for running shoes" might include users who visited running gear pages a certain number of times in the last 30 days, searched for terms like "marathon training plan" or "best trail runners," or landed on a checkout page for athletic footwear without completing the purchase. Data providers build and sell these segments. Some of the underlying data comes from publishers who share it directly. Some comes from data brokers who've aggregated it across many sources. And some of it is modeled, meaning a user wasn't actually observed doing any of those things, but statistically resembles people who were, so they got included anyway. You can be in a segment you never directly qualified for, simply because your browsing history rhymes with someone who did.
Lookalike modeling takes this further. An advertiser uploads a list of their best customers, and the platform finds other users who behave similarly and expands the target audience outward. The quality of a lookalike depends almost entirely on the seed list. A brand that truly understands its customer base, using a list of people who have actually bought, stayed loyal, and returned, gets a genuinely useful lookalike. A brand that uploads everyone who ever opened a promotional email gets a lookalike of people who open promotional emails, which is a much less interesting group.
Frequency capping is the mechanism meant to stop this from getting out of hand. Advertisers can set a limit on how many times the same user sees the same ad within a given window. In theory, you see the shoe ad twice, get the message, and the campaign moves on. In practice, frequency capping breaks in a few reliable ways: the cap is set per DSP rather than across all of them, so five different DSPs each think they've only shown you the ad twice when you've actually seen it ten times; or the cap is set against a cookie ID that refreshes, so the system thinks you're a new user every few days; or someone just didn't set a cap at all because they were in a hurry. The result is that ad that followed you for two weeks across every website including one about 14th century grain prices. That wasn't a strategy. That was a cap that didn't work.
So when you see running shoe ads three days after Googling marathon training plans, here's what actually happened: your browsing put you into a segment, a DSP matched your identifier to that segment when your bid request came in, they bid enough to win, and nobody set a reasonable frequency cap. The internet didn't read your mind. It matched a string of characters to a row in a database and showed you the same ad until you noticed. Less mystical than it feels, and, depending on how you feel about it, either reassuring or quietly unsettling.
The Money
Let's say an advertiser wins an impression at a $10 CPM. CPM means cost per thousand impressions, so that's one cent per ad shown. Small number, but this happens billions of times a day.
That one cent doesn't reach the publisher intact. The exchange takes 15 to 20 percent off the top. The DSP charges the advertiser a platform fee before the bid even hits the exchange. If the advertiser bought a data segment to power the targeting, that cost stacks on too. By the time the money travels from advertiser to publisher, a meaningful chunk of it has been absorbed by the platforms in between.
But there are other costs between the advertiser and the publisher. A DSP typically charges a percentage of media spend as a platform fee, which comes out before the bid even hits the exchange. If the advertiser bought a third-party data segment to power the targeting, that data cost sits on top of the media cost. A real-world effective CPM for a targeted campaign impression, once all fees and data costs are stacked, can be meaningfully higher than the exchange clearing price alone.
This is one of the things that took me a while to fully internalize when I started in the industry. The bid that wins an auction is not what the advertiser actually pays, and the revenue the publisher receives is not what was bid. The spread between advertiser spend and publisher revenue is where much of the AdTech ecosystem makes its money. It's not a secret, but it's also not something platforms go out of their way to explain. The actual math behind any given impression involves several parties taking cuts at different points in the chain, and the opacity of that chain has been a source of industry tension for years.
The Association of National Advertisers did a study a few years back and found that for every dollar spent on programmatic advertising, roughly 50 cents reached an actual media impression. The other 50 cents went to various intermediaries along the chain. The industry response was largely "yes, that's how it works," which is technically accurate and also not a great look.
The one thing everyone in the chain agrees on is that the system works. It just works slightly better for the people in the middle.
The Part That's Actually Hard
The auction mechanics are standardized. The hard part is the data that feeds into it.
I've spent years building audience data infrastructure: pipelines that process behavioral signals at scale, identity systems that match IDs across platforms and resolve them into usable profiles, reporting that tells you whether the targeting actually worked or just looked like it did on a dashboard measuring the wrong thing.
The volume is significant on its own. A mid-sized publisher generates tens of millions of events per day. A data platform processing audience signals across many publishers is working with orders of magnitude more. Raw events have to be ingested, deduplicated, sessionized, enriched with context, matched against identity graphs, and turned into segment memberships, all fast enough to be useful in a system where the bid request expires in 100 milliseconds anyway.
Signal quality is the unglamorous core of this work. A behavioral signal has to mean what you think it means. Someone who visited a car insurance page might be in-market for car insurance, or they might be doing competitive research, or they clicked the wrong link, or they're a bot. The proportion of garbage in a raw event stream is higher than most people assume, and the impact of not cleaning it flows downstream into targeting that's built on noise. The advertiser never sees the noise directly. They just see performance numbers that don't make sense and wonder if the targeting was off.
The matching problem is similarly unforgiving. A user who reads news on a laptop in the morning and scrolls their phone in the evening is one person, but they appear as two different IDs in the raw data. Getting that match right, without false positives that merge profiles that shouldn't be merged, is genuinely hard. Do it wrong and you're targeting two people as one, or showing the same person the same ad on both devices and blowing through your frequency cap without knowing it. Campaign performance data goes wrong in ways that aren't always obvious from the numbers alone.
Most of the visible complexity in AdTech lives in the auction: the bidding logic, the creative trafficking, the pacing algorithms. But the invisible complexity, the part that actually determines whether any of it works, lives in the data infrastructure underneath. Getting that right is most of the job.
The auction closes in 100 milliseconds, but the work that makes it mean something takes considerably longer.